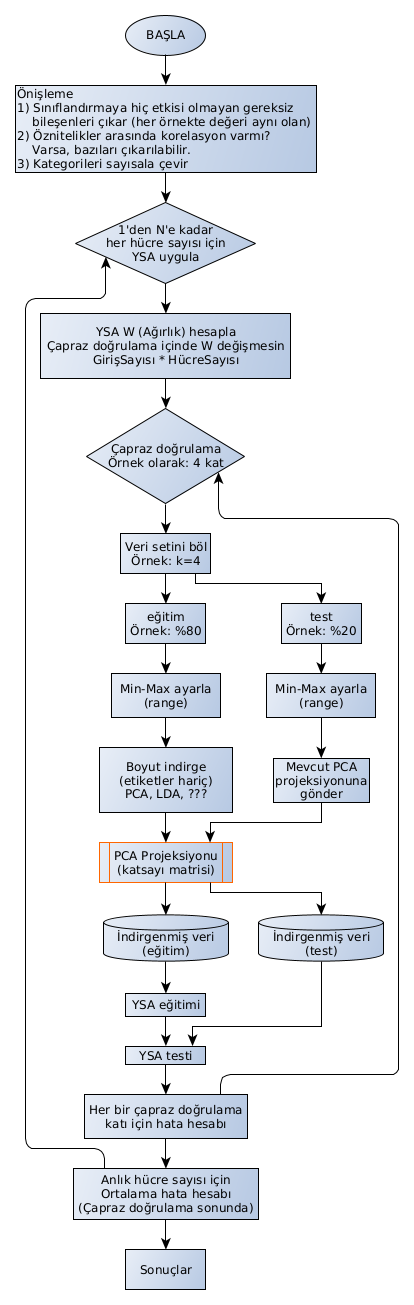
Veri ön işleme ve Yapay Sinir Ağı eğitimi akış diyagramı
Önceki doktora tez çalışmam sırasında çıkardığım bir akış diyagramıydı. Haftalarca çalışmıştım sırf bu işlerin sırasını, amacını ve uygulamasını anlamak için. O iş yarım kaldı, şimdi bambaşka bir konudayım. Yazdığım notlar ziyan olmasın, birilerinin işine yarar belki.
Ben ELM çalıştığım için, onda iterasyon yapılmıyor. Tek seferde tüm veriyi gönderip ağırlıklar hesaplanıyor. “İterasyon nerede?” diye aramamanız için baştan yazdım.
Veri seti olarak ta KDD kullanmıştım. 41 öznitelik (attribute) ve bir sınıf/etiket (class/label) var veri setinde.
Kodlamada Python ve GNU Octave ile çalışmıştım.
Yazıyı yazarken faydalandığım kaynak linkler:
- https://stats.stackexchange.com/questions/55718/pca-and-the-train-test-split
- https://machinelearningmastery.com/data-preparation-without-data-leakage/
Metinsel özet
- Önce mutlaka metin editöründe (tercihen Notepad++ veya Linux’ta Notepadqq) açarak, gözle muayene yap. Veriler hangi işaretle ayrılmış? Göze çarpan anormallik (değişik karakterler, uyumsuz satırlar, büyük/küçük harfler, vb.) var mı?
- Açabiliyorsan veri setini hesap tablosu (tercihen Libreoffice Calc) ile aç. Verilerini biraz tanı. Veri türleri kategorik mi, numerik mi öğren. Veri türleri konusunda aşağıda bir başlık altında birkaç görsel paylaştım. Veri setindeki değerlerin min/max/ort değerlerine bak. Değerlerde normalizasyon gibi işlem gerekip gerekmeyeceğine dair yorum yap.
- Verilerde temizleme yapılacaksa yap.
- Yaptığın her işlemi not et. Çalışmanı yayınlayacaksan bu kısım çok önemli.
- Gerçekten önemli bir işlem değilse, veriye çok müdahale etmemeyi tercih et.
- Elle teker teker müdahale etmekten kaçın. Örneğin, sayısal verilerde ondalık hane “.” ile ayrılmışsa ve “,” ile ayrılmasını istiyorsan; “zaten sayısı az, elle yaparım” deme. Bu tarz değişiklikleri ya kod içerisinde topluca değiştir ya da metin editöründe “Bul/Değiştir” seçeneği ile topluca değiştir.
- Veri setinde kullanmayı düşünmediğin sütunları çıkar.
- Veri setinde kullanmayacağın ya da bütüne zarar veren değerler varsa, bunları çıkar. gruptaki erkeklerin obezite riskine çalışıyorsan, kadınları veriden çıkarabilirsin mesela.
- Gerekli ise, RegEx ile metni incele (veya gerekli ifadeleri ayıkla).
- Kategorik veriler varsa, bunları YSA ile işleyemeyeceğin için numerik hale getir.
- Çapraz doğrulamaya (cross validation) başla
- Test/eğitim ayır
- Min-max scale yap. Sadece gerekli olan sütunlarda tabii. 0-1 arasında olsun. normalizasyon yapacaksan (standart sapma falan girecekse işin içine, eğitim ve test veri setine ayrı yapmak lazım, test verisinin etkisi eğitimi kirletmesin diye)
- PCA yapacaksan, sadece eğitime yap.
- Modeli fit et (eğit)
- Test verisinde, az önce elde ettiğin PCA projeksiyonuna göre boyut indirgeme yap. test ve eğitim verilerinde boyutlar farklı olur.
- Boyut indirgenmiş test verisini modele gönder - Hata hesabı yap
Kullandığım bazı yöntemler
Ölçeklendirme (scaling)
Buna genellikle normalizasyon deyip geçiyoruz. Ben de aslında bu uygulamada normalizasyon yaptım. Ancak normalizasyon, veriyi belirli bir aralığa getirmek için kullanılabilen yöntemlerden sadece birisi. Standardizasyon, min-max normalizasyon, ortalama normalizasyonu, vb. farklı yöntemler bulunmaktadır.
Veri boyut indirgeme (dimensionality reduction)
Temel bileşen analizi (PCA) yöntemini tercih etmiştim. Bunun için pca fonksiyonu kullanmıştım. PCA uygulanarak %95 doğruluk elde etmek için 11 temel bileşen elde edildi. 41 sütun veri ile çalışmak yerine 11 sütun veri ile çalıştım.
- DİKKAT: PCA gibi temel bileşen analizi uygulamaları veri setini bozar. Veri setindeki onlarca sütunu temsil eden bambaşka veriler koyar. İşlenecek veri sayısını azalttığı için veri işleme aşamasını ucuzlatır.
- PCA yapmadan önce kategorik veriler sayısala çevrilmelidir.
- PCA öncesinde normalizasyon yapılması tavsiye ediliyor.
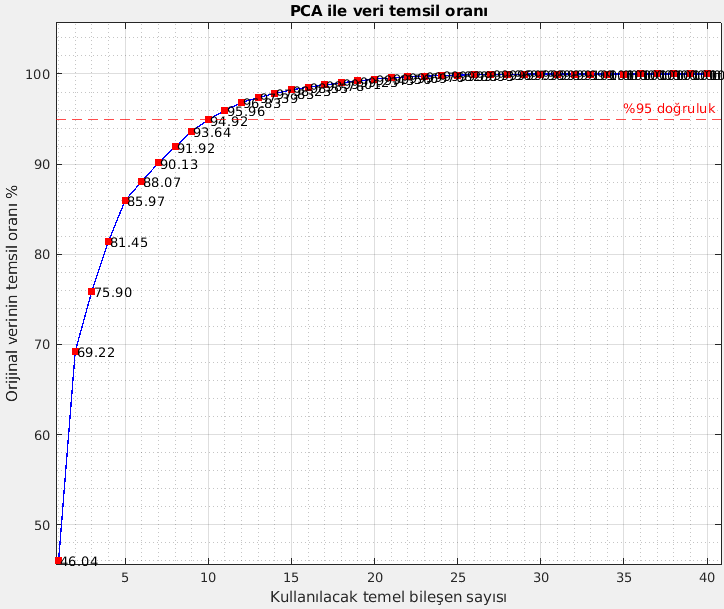
Bana yeterli olan doğruluk değerini saplamak için kaç temel bileşen almalıyım? Ben %95 doğruluk değerini yeterli gördüğüm için 11 bileşen almıştım. “%85 doğruluk yeterli” deseydim, 5 bileşen yeterli olacaktı.
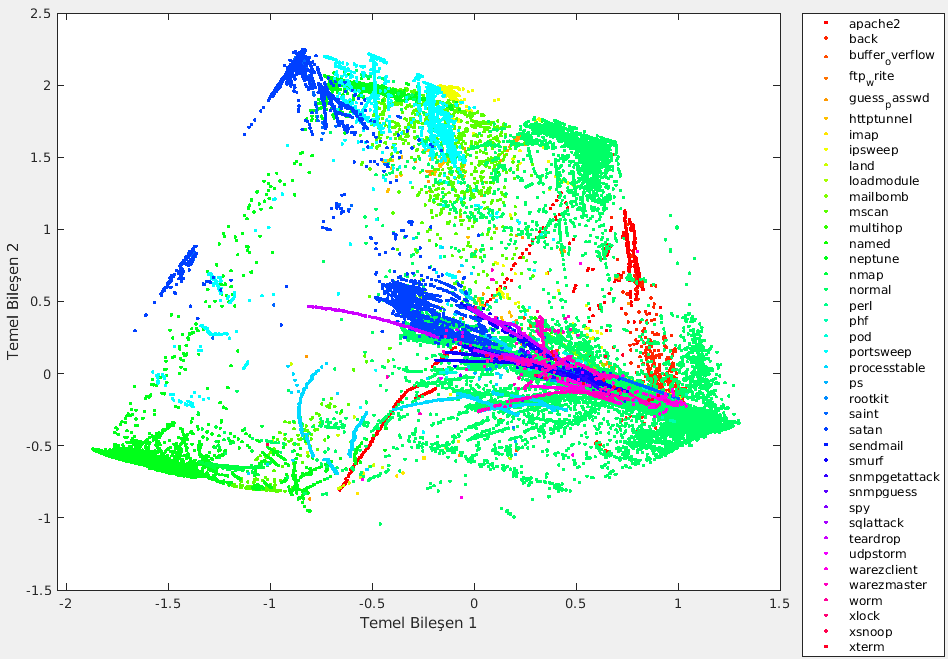
İlk 2 temel bileşen ile bile %75 doğruluk elde edilebildiğini önceki görselden görebilirsiniz. Burada da bu 2 bileşene göre tüm verilerin 2 boyutlu koordinat sisteminde dağılımı (kümelenmesi, sınıfları) görülüyor.
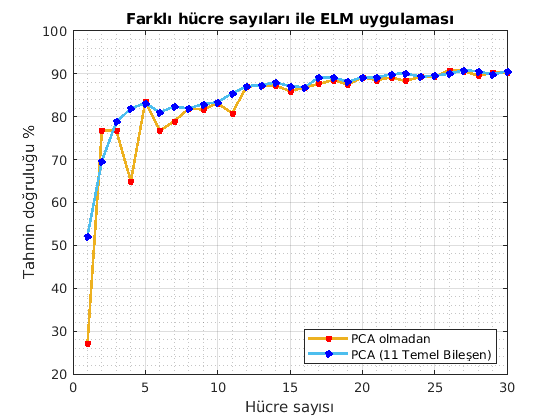
İki farklı eğitim işleminin sonucunda ölçülen doğruluk değerinin karşılaştırması. PCA yapılmadan önce 41 öznitelik ile yapılan turuncu, PCA ile çıkarılan ilk 11 temel bileşen ile yapılan eğitim ise mavi çizgi. Yatay sütun, ELM YSA içerisindeki hücre sayısını gösteriyor. Hücre sayısı arttıkça, doğruluk artıyor normal olarak. Belirli bir hücre sayısından sonra, mavi ve turuncu çizgiler iyice yaklaşıyor. Demek ki, en az 15 hücre kullanırsam, 11 bileşen ile bile veri oldukça iyi temsil edilebiliyor.
Öznitelik seçimi (feature selection)
Hangi öznitelikler veri setimi hangi oranda temsil edebiliyor?
Bunun için fscmrmr fonksiyonu kullandım. MRMR yöntemi ile öznitelik seçimi yapıldı. 20 numaralı sütunun gereksiz olduğu görülüp veri setinden kaldırıldı. 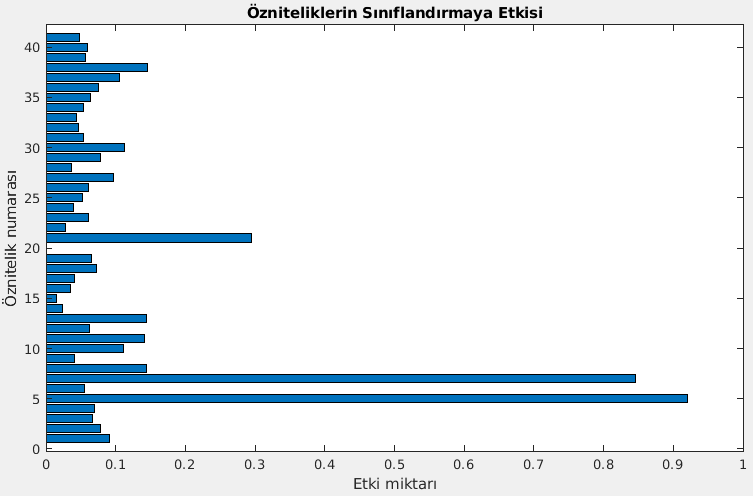
Veri setindeki 41 özniteliğin her birinin ayrı ayrı sınıflandırmaya ne kadar katkısı olduğunu ölçtüm. 20. sütunun sınıflandırmada hiç bir halta yaramadığını öğrendim :) Hatta şunu da görebiliyoruz: Sadece 5. sütunu alsam bile çok büyük doğruluk oranında sınıflandırma yapabilirim.
Çapraz Doğrulama (Cross Validation)
Veri setini istediğimiz sayıda parçaya bölüyor. Teker teker her bir parçanın test verisi olmasını sağlayarak diğer kısımları de eğitim olarak kullanıyor. Bu sayede veri setindeki her bir eleman hem test hem de eğitim verisi olarak işlenmiş oluyor. Bunların ortalamasını aldığınızda, tarafsız (“tarafsız” doğru ifade olmadı sanki) bir sonuç elde etmek için elinizden geleni yapmış oluyorsunuz. Bunun için cvpartition fonksiyonunu kullandım.
Çapraz doğrulama yapmazsanız, verilerin bir kısmı ile eğitip diğer kısmı ile test yapmış olursunuz. Tesadüfe bağlı olarak, eğitim/test gruplarına benzer verilerin gelmesi durumunda bambaşka sonuçlar elde edebilirsiniz.
Dikkat edilecek bazı konular
Maalesef birçok akademik çalışmada bunlara dikkat edilmediğini gördüm. Bu nedenle yazıyorum:
- Veri setinde normalizasyon ve PCA gibi işlemler eğitim ve test setlerine ayrı ayrı yapılmalıdır. Veri seti bölünmeden önce yapılırsa, “veri sızıntısı (data leakage)” oluşur. Verinin bütününü alıp bir hesap yapan algoritmalarda buna dikkat etmek gerekir. Mesela veriyi önce normalize edip sonra eğitim-test ayırırsanız, eğitim sırasında kullandığınız verilerde, sadece test’te kullanılması gereken izler olur. Normalizasyon işlemindeki formüle test verileri de girmiştir çünkü. Eğitim verisi kirlenmiş olur bu şekilde.
- PCA için bir diğer dikkat edilmesi gereken nokta, eğitim verisine PCA yapıldıktan sonra test verisine ayrıca PCA yapılmalıdır. Ama bunu yaparken; test verileri de eğitim verisinde oluşturulan PCA projeksiyonuna gönderilmelidir. Sıfırdan yeni PCA yapılırsa, veriler yine kirlenir.
- Çapraz doğrulama yapılmasına engel bir durum yoksa, yapılmalıdır. Yapılmazsa, her seferinde farklı sonuç elde edersiniz. Maalesef birçok akademik çalışmada bu şekilde yapılıp, en beğenilen sonucu paylaşmak şeklinde yol izlenmiş.
- Çapraz doğrulama varsa, PCA gibi işlemler çapraz doğrulama içinde yapılmalıdır.
- Çapraz doğrulama varsa, YSA ağırlıklarının her kat içinde değişmesi/değişmemesi durumu değerlendirilmelidir. Duruma göre ikisi de uygulanabilir.
- Yukarıda yazdım ama yine yazıyorum. Kodları ve data’yı birlikte paylaşmıyorsanız, yaptığınız çalışmanda şaibe kalmaması için bunlara dikkat etmelisiniz. Ve algoritmanızı (veride yaptığınız işlemleri) çok net bir şekilde açıklamalısınız.
Veri Türleri
Bu konuda daha önce kısa bir yazı yazmışım. Bir link iki de görsel bırakıyorum:
https://ozalpmurat.github.io/posts/kategorik-veri-turlerini-YSAya-gonderme/
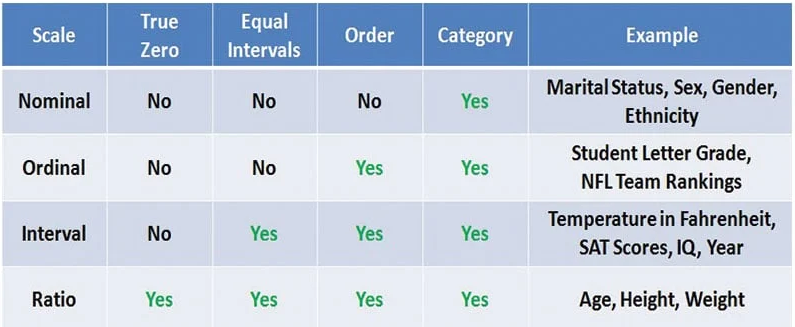
*Görsel kaynağı: https://microbenotes.com/nominal-ordinal-interval-and-ratio-data/**
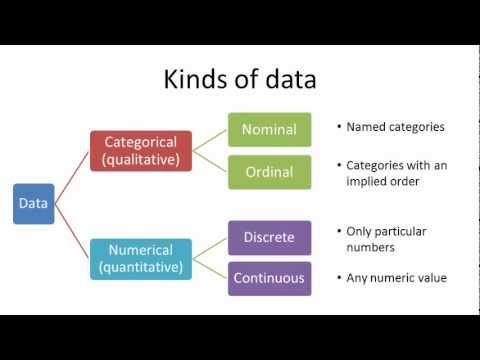
Görsel kaynağı: https://youtu.be/7bsNWq2A5gI